






Expand your QA program without spending on new hires. Use AI-powered automation to reduce repetitive tasks, AI Assist to reduce evaluation times and automated workflows to assign targeted lists for evaluation, freeing up valuable QA resources.

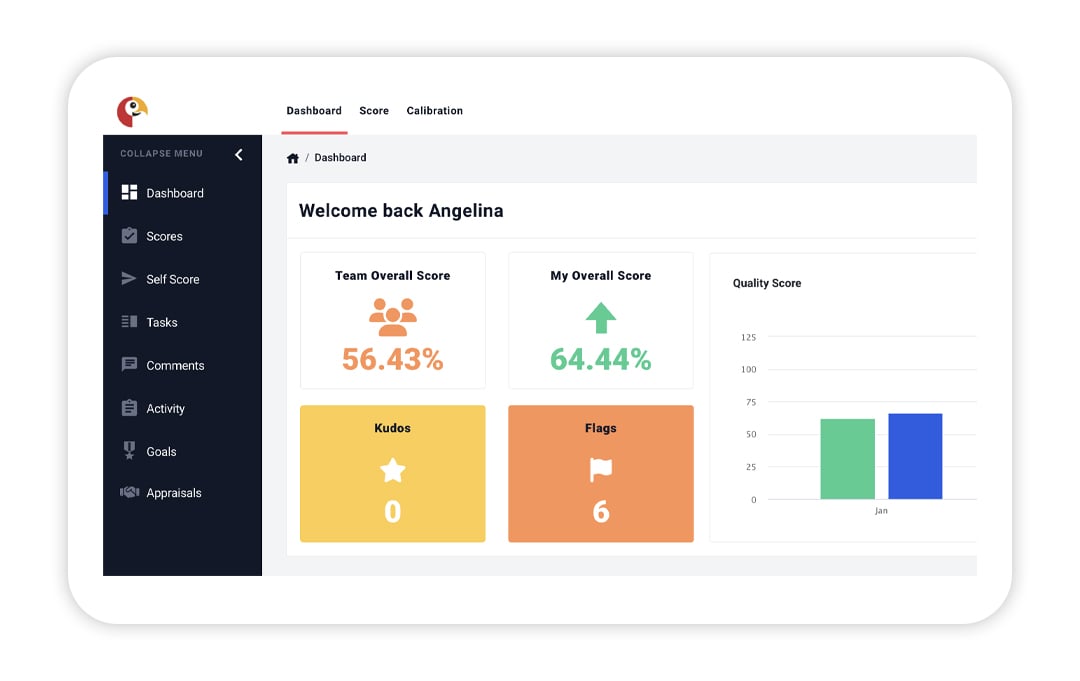
Boost employee retention and engagement with personalized agent dashboards, immediate feedback, and tailored coaching plans.

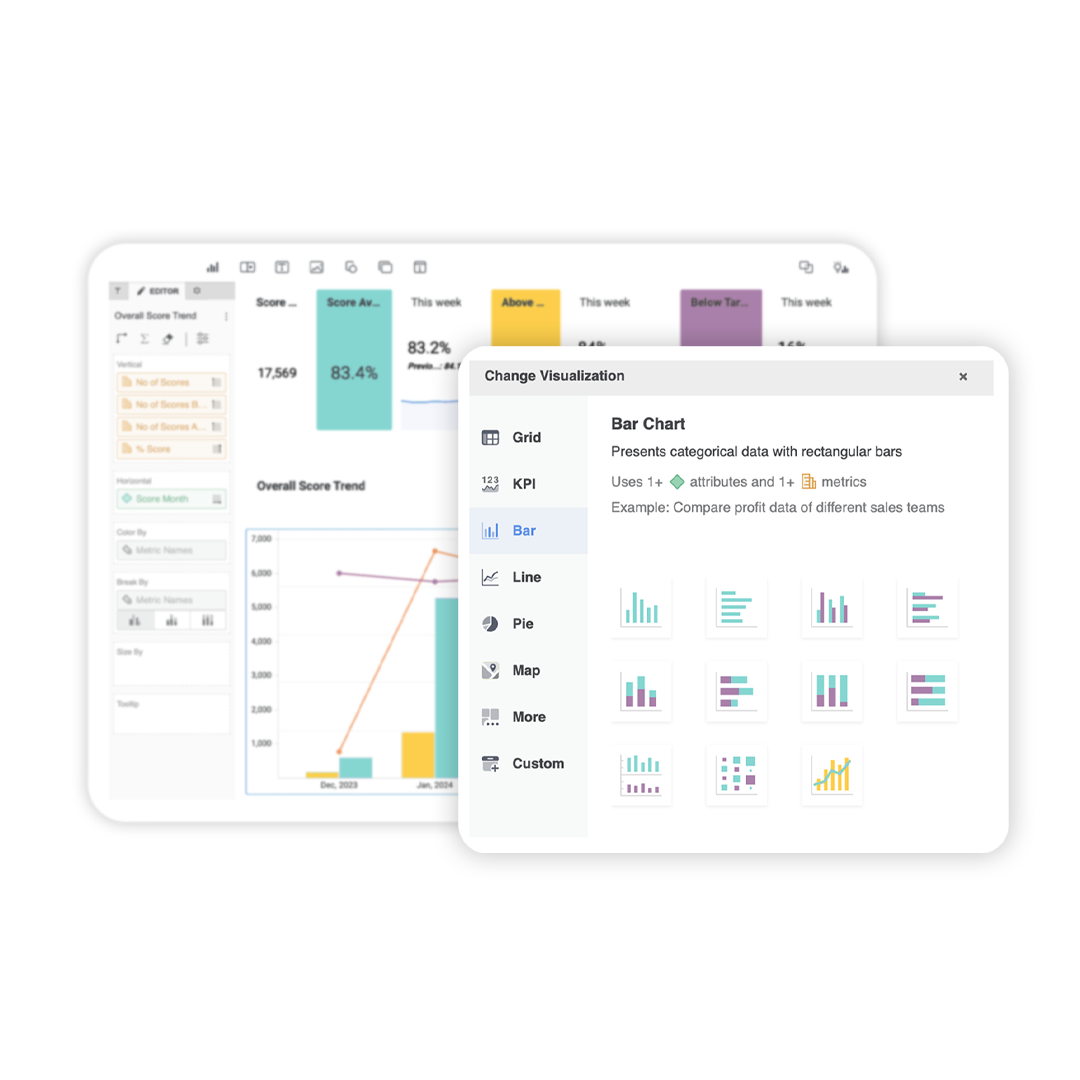
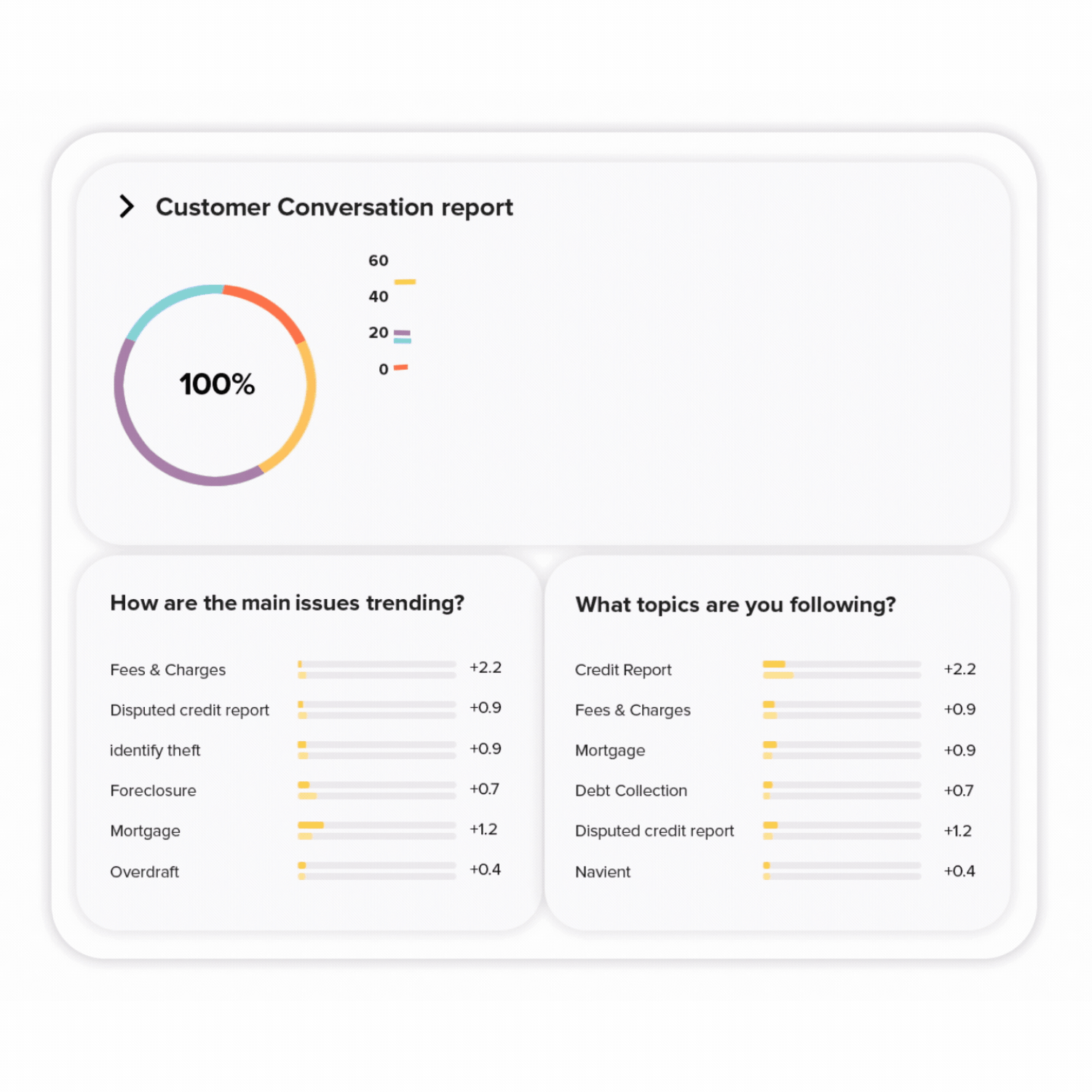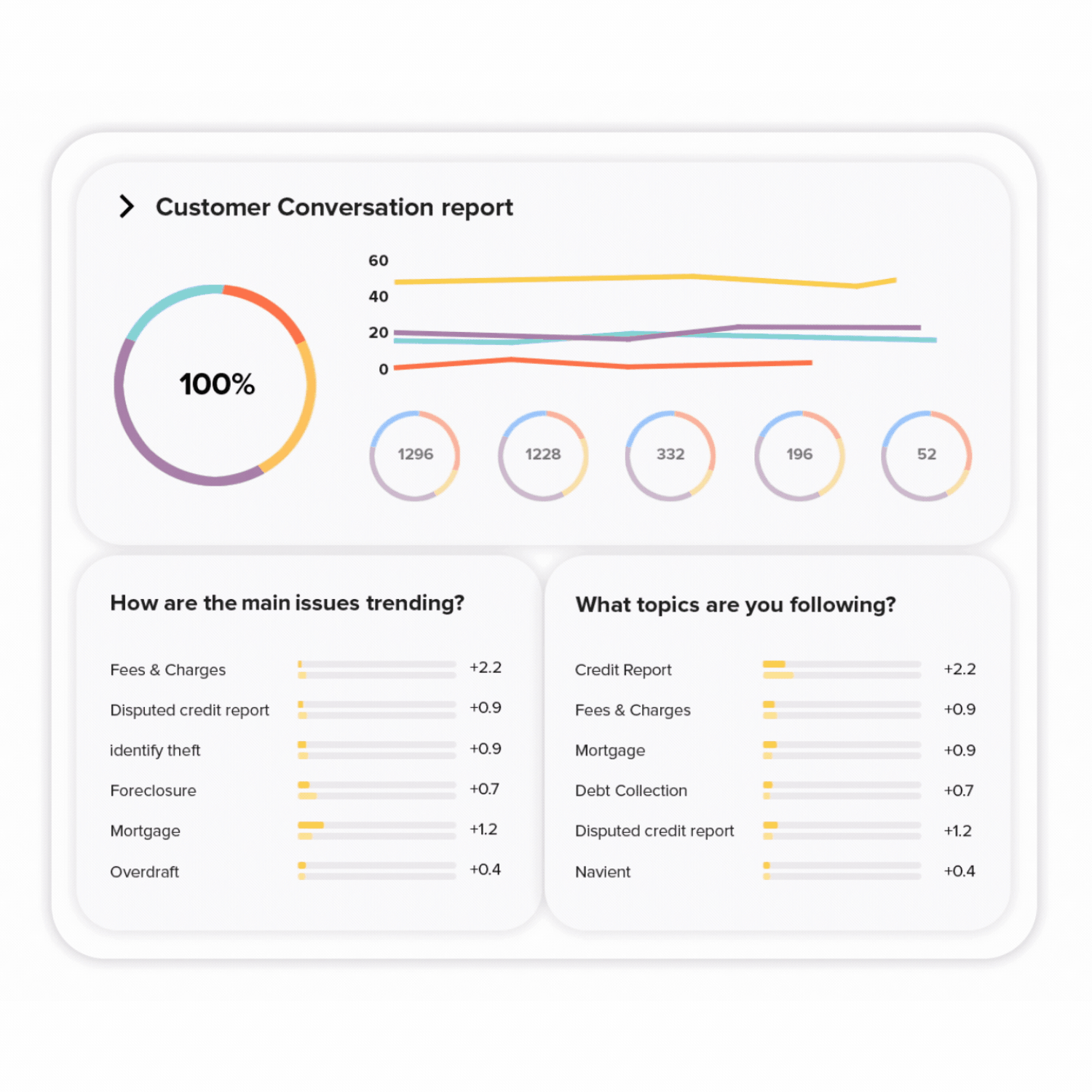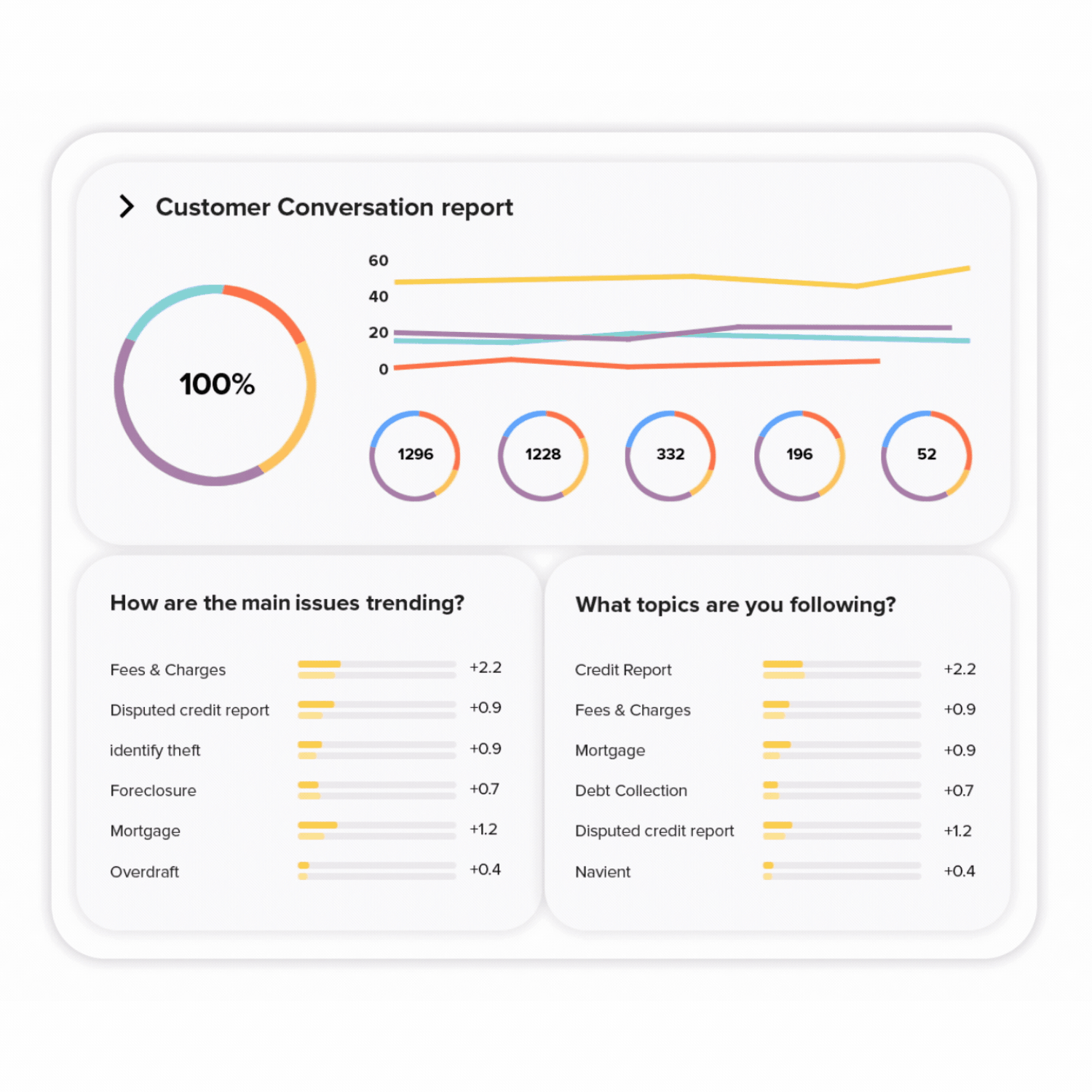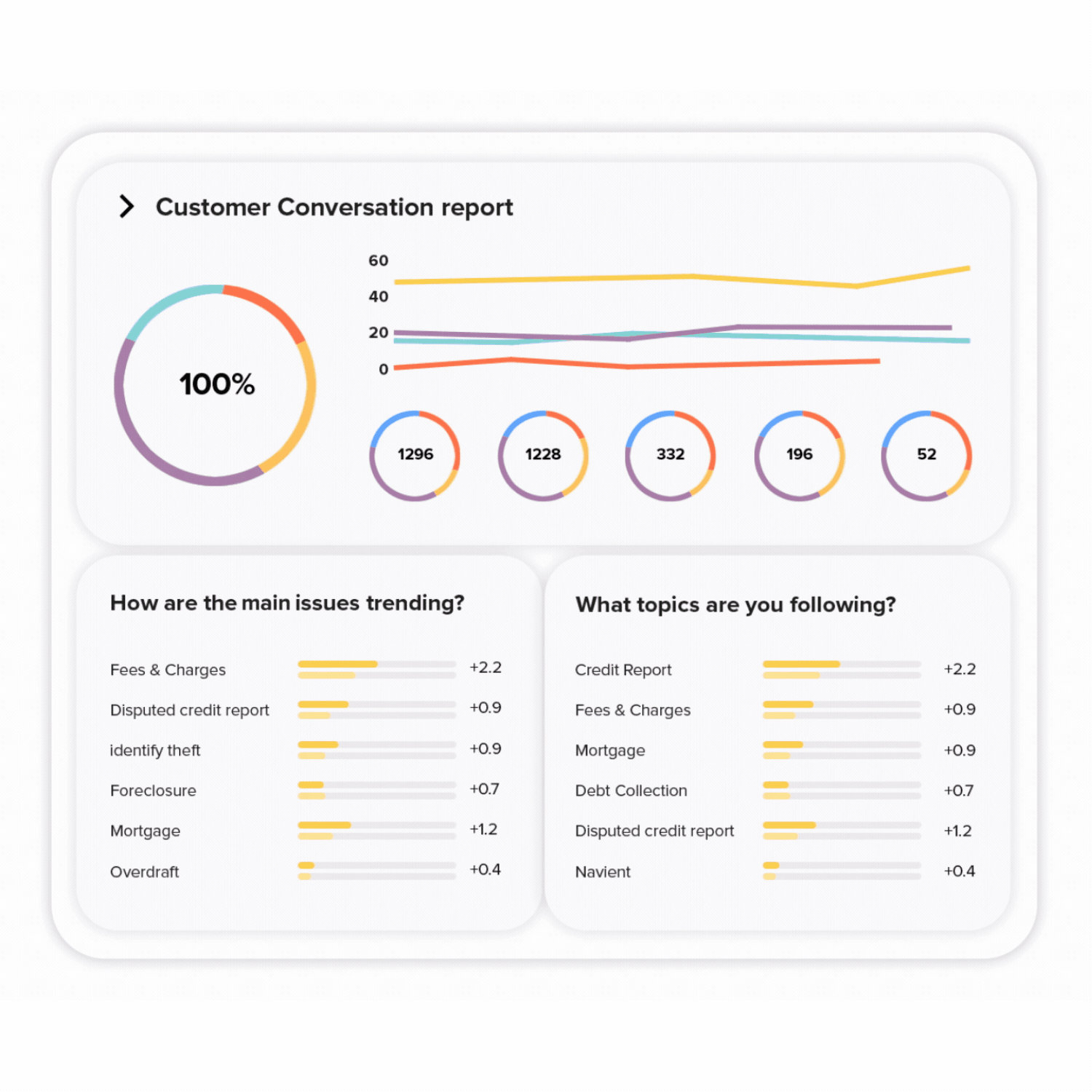
Leverage all that customer and QA data to spot trends and patterns. Visualize with custom dashboards designed by you for your needs. Easily share dashboards and reports across the business to inform stakeholders and management.


Scorebuddy QA is an invaluable source of feedback-if something isn't working, this information needs to be shared immediately. Through evaluations completed on Scorebuddyy, we can analyze 100% of our interactions to identify and promptly remediate the issues that really matter to customers.
Business Assurance Manager
PTSB